Η oπτική αναγνώριση χαρακτήρων του λογισμικού Google λειτουργεί τώρα για όλες τις γλώσσες της Νότιας Ασίας



Μια διαδικασία βήμα-βήμα για να χρησιμοποιήσετε το λογισμικό της οπτικής αναγνώρισης χαρακτήρων της Google που υποστηρίζει σχεδόν όλες τις κύριες γλώσσες της Νότιας Ασίας. Εικόνα από Subhashish Panigrahi, άδεια CC-by-SA 4.0.
Το λογισμικό oπτικής αναγνώρισης χαρακτήρων (OCR) από την Google λειτουργεί τώρα για περισσότερες από τις 248 γλώσσες, συμπεριλαμβανομένων όλων των κύριων γλωσσών της Νότιας Ασίας, είναι εύκολο στη χρήση και λειτουργεί με πάνω από 90% ακρίβεια για τις περισσότερες γλώσσες.
Το λογισμικό OCR ήταν εξαιρετικά ωφέλιμο για τη μελέτη της γλώσσας, βοηθώντας να εξαχθεί κείμενο από εικόνες από σχεδόν κάθε τυπωμένο κείμενο – και μερικές φορές ακόμη και από χειρόγραφα, το οποίο ανοίγει τον δρόμο για παλιά κείμενα, χειρόγραφα, και πολλά άλλα.
Ο Ketan Pratap γράφει στο NDTV Gadgets:
Οι χρήστες μπορούν να αρχίσουν να χρησιμοποιούν τις δυνατότητες του OCR στο Drive εισάγοντας σαρωμένο έγγραφο σε μορφή PDF ή σε μορφή εικόνας, τα οποία μπορούν να ανοίξουν μετά κάνοντας δεξί κλικ στο έγγραφο στο Drive για να ανοίξει με το Google Docs. Μετά επιλέγοντας αυτό, ανοίγει ένα έγγραφο με την αρχική εικόνα μαζί με το εξαγόμενο κείμενο , το οποίο μπορεί να επεξεργαστεί από τον χρήστη. Η Google σημειώνει ότι οι χρήστες δεν θα πρέπει να καθορίσουν τη γλώσσα του εγγράφου, καθώς το OCR στο Drive θα την προσδιορίσει αυτόματα. Η δυνατότητα του OCR στο Google Drive θα είναι διαθέσιμο και σε Drive για Android.
Στο Twitter, πολλοί χρήστες έχουν καλωσορίσει με εορταστικό τρόπο αυτό το νέο χαρακτηριστικό από την Google:
Optical Character Recognition #OCR in Google Drive recongnizes many indic languages including #Kannada give it a try http://t.co/99UkCJQ6gb
— Omshivaprakash (@omshivaprakash) August 28, 2015
Οπτική Αναγνώριση Χαρακτήρων #OCR στο Google Drive αναγνωρίζει πολλές ινδικές γλώσσες, συμπεριλαμβανομένης της #Kannada δοκιμάστε το http://t.co/99UkCJQ6gb
@shylobisnett if you have access to a scanner, you can do OCR through google drive. works a bit faster.
— Whet Moser (@whet) August 27, 2015
@shylobisnett αν έχετε πρόσβαση σε έναν σαρωτή, μπορείτε να κάνετε OCR μέσω του Google Drive. λειτουργεί λίγο πιο γρήγορα.
Wow. Searching Google Drive for a keyword also returns results for images containing that keyword in the image. Didn't realise it did OCR.
— Mark Osborne (@mosborne01) August 25, 2015
Ουάου. Ψάχνοντας στο Google Drive για μια λέξη-κλειδί επιστρέφει επίσης αποτελέσματα για εικόνες που περιέχουν τη λέξη-κλειδί στην εικόνα. Δεν είχα συνειδητοποιήσει ότι το έκανε το OCR.
Συνήθως το λογισμικό OCR έχει δυσκολία στην ανάγνωση του κειμένου σε παλιά έγγραφα ή σελίδες με ατέλειες και τα σημάδια του μελανιού, δείχνοντας ασυναρτησίες αντί ευανάγνωστο κείμενο.
Η σελίδα υποστήριξης της Google σε αυτό το έργο παρουσιάζει πρόσθετες λεπτομέρειες σχετικά με την μορφοποίηση χαρακτήρων, όπως και την ικανότητά του να διατηρήσει έντονη και πλάγια γραμματοσειρά στο τελικό κείμενο :
Κατά την επεξεργασία του εγγράφου σας, προσπαθούμε να διατηρήσουμε τη βασική μορφοποίηση κειμένου, όπως έντονη και πλάγια γραμματοσειρά, το μέγεθος και τον τύπο της, καθώς και τις αλλαγές γραμμής. Ωστόσο, η ανίχνευση αυτών των στοιχείων είναι δύσκολη και δεν μπορεί πάντα να πετύχει. Άλλες μορφοποιήσεις του κειμένου και στοιχεία της δόμησης όπως κουκκίδες και αριθμημένες λίστες, πίνακες, στήλες κειμένου, και υποσημειώσεις ή σημειώσεις του τέλους είναι πιθανό να χαθούν.
Για ορισμένες από τις γλώσσες, όπως Μαλαγιάλαμ και Ταμίλ, το OCR λειτουργεί με σχεδόν 100% ακρίβεια και περιλαμβάνει υποστήριξη για τη μορφοποίηση πραγμάτων όπως η αυτόματη περικοπή, που χωρίζει το κείμενο με την απόρριψη εικόνων, και αγνοώντας το χρώμα φόντου, εξηγεί ο χρήστης Tamil και το Wikimedian Ravishankar Ayyakkannu στο Facebook:
[…] Στο Google Tamil το OCR λειτουργεί με ακρίβεια 100%! Κάνετε συνεχείς δοκιμές με διάφορα δείγματα και να σχολιάσουν εδώ. Oi επιδόσεις ήταν ίδιες για πολλές άλλες ινδικές γλώσσες επίσης. […] Αυτόματες αποκοπές, απόρριψη εικόνων και έγχρωμο φόντο. Αναγνωρίζει διαφορετικές διατάξεις. Θα μπορούσα να βρω μόνο 1 λάθος σε όλη τη σελίδα. Δοκιμές τελευταία σε Vikatan – https://docs.google.com/…/1OXre4…/edit.. […]
(Οι χρήστες γλωσσών Bangla, Malayalam, Kannada, Odia, Tamil, και Telugu σχολίασαν στην ίδια δημοσίευση με πληροφορίες μετά από τη δοκιμή του ενημερωμένου λογισμικού OCR. Για μερικά γραπτά, όπως σε Gurmukhi (που χρησιμοποιείται για να γράφεται η Punjabi), αποδεικνύεται ότι το αποτέλεσμα μετά το OCR είναι αρκετά φτωχό. Αυτό οφείλεται σε μεγάλο βαθμό σε ακατανόητους χαρακτήρες, κατά τη δοκιμή με μια εικόνα παρμένη από το Punjabi Wikipedia.)
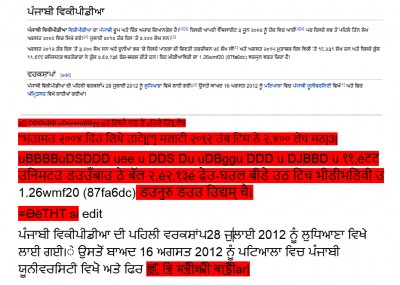
Προβλήματα με γραφή Gurmukhi έπειτα από τη χρήση του Google OCR. Screenshot, Punjabi Wikipedia.
Αυτό είναι ένα αρκετά μεγάλο άλμα για τις γλώσσες με πολλά παλιά κείμενα που δεν έχουν ακόμη ψηφιοποιηθεί. Παλιά και πολύτιμα κείμενα σε πολλές γλώσσες θα μπορούσαν τώρα να ψηφιοποιηθούν και να μοιράζονται μέσω του διαδικτύου χρησιμοποιώντας πλατφόρμες όπως την Wikisource και θα μπορούσαν να διατηρηθούν και να διατεθούν για την ανταλλαγή γνώσεων.
Το OCR της Google χρησιμοποιεί μερικώς το Tesseract— μια μηχανή OCR που κυκλοφόρησε ως freeware. Αναπτύχθηκε ως ένα έργο της κοινότητας μεταξύ των ετών 1995 και 2006 (και αργότερα εξαγοράστηκε από την Google), το Tesseract θεωρείται ως μία από τις πιο ακριβές μηχανές OCR στον κόσμο και λειτουργεί για πάνω από 60 γλώσσες. Ο βασικός κώδικας υπάρχει τώρα στο https://github.com/tesseract-ocr. Δείτε εδώ για τις εξελίξεις του OCR σε διάφορα γραπτά κείμενα της Νότιας Ασίας.

Αυτό το άρθρο προέρχεται από το Rising Voices, ένα έργο του Global Voices που βοηθάει στην διάδοση των μέσων των πολιτών σε μέρη που κανονικά δεν έχουν πρόσβαση σ' αυτά. · Όλα τα άρθρα





